Openindiana/Solaris 11 und COMSTAR iSCSI-Target in 5 Minuten
openindiana und iSCSI mit COMSTAR
Die Jungs von SUN haben sich irgedwann einmal gedacht, wäre es nicht toll wenn wir Dinge wie iSCSI, FCoE, FC usw… Einfach in einem großen Framework zusammenfasst.
Damit ersetzt nun COMSTAR den alten iSCSI Target Deamon. Damit ändert sich natürlich auch die Konfiguration… Wie an so vielen Stellen beim Wechsel von Solaris 10 auf Solaris 11 / Opensolaris…
Ich möchte hier im Kurzen die Einrichtung eines einfachen iSCSI Targets basierend auf ZFS für einen Microsoft Windows Host beschreiben. Ich nutze dafür ein Openindiana System. Dieses basiert auf dem letzten Opensolaris welches dann später ins aktuelle Oracle Solrais 11 übergegangen ist.
Na dann mal los!
In diesem Testsystem habe ich für dieses Beispiel eine gesonderte Festplatte vorgesehen. Auf dieser erstelle ich zuerst einen neuen ZFS Pool:
root@iscsi-host:/# zpool create iscsi-target-pool c4t2d0 root@iscsi-host:/# zpool list iscsi-target-pool NAME SIZE ALLOC FREE EXPANDSZ CAP DEDUP HEALTH ALTROOT iscsi-target-pool 19,9G 124K 19,9G - 0% 1.00x ONLINE -
In diesem Pool lege ich nun ein weiters ZFS Volume an, welches später das eigentliche Ziel wird:
root@iscsi-host:/# zfs create -V 10g iscsi-target-pool/iscsi_10gb-lun01 root@iscsi-host:/# zfs list iscsi-target-pool/iscsi_10gb-lun01 NAME USED AVAIL REFER MOUNTPOINT iscsi-target-pool/iscsi_10gb-lun01 10,3G 19,6G 16K -
Wie man sieht habe ich das ZFS Volume auf eine Größe von 10GB begrenzt. Das macht natürlich Sinn wenn man kurz darüber nachdenkt. Sonst würde die Poolgröße das jeweilige Target begrenzen und wenn man mehrere davon in einem Pool hat… Um die nötigen Grundlagen abzuschließen starte ich nun noch die nötigen Dieste.
root@iscsi-host:/# svcs stmf STATE STIME FMRI disabled 12:32:40 svc:/system/stmf:default root@iscsi-host:/# svcadm enable stmf root@iscsi-host:/# svcs stmf STATE STIME FMRI online 13:02:50 svc:/system/stmf:default root@iscsi-host:/# stmfadm list-state Operational Status: online Config Status : initialized ALUA Status : disabled ALUA Node : 0
Zuerst schaue ich mir den Status des stmf (SCSI Target Mode Framework) an; es ist deaktiviert. Nach dem aktivieren und prüfen frage ist das stmf mit dem eigenen stmfadm(in) nach dem Status. Es soll ein iSCSI Target werden, dafür fehlt mir noch das folgende Packet:
root@iscsi-host:/# pkg install -v /network/iscsi/target Zu installierende Pakete: 1 Geschätzter verfügbarer Speicherplatz: 9.91 GB Geschätzter Speicherplatzverbrauch: 234.32 MB Boot-Umgebung erstellen: Nein Sicherung der Boot-Umgebung erstellen: Ja Zu ändernde Services: 1 Boot-Archiv neu erstellen: Ja Geänderte Pakete: openindiana.org network/iscsi/target None -> 0.5.11,5.11-0.151.1.8:20130721T131345Z Services: restart_fmri: svc:/system/manifest-import:default DOWNLOAD PAKETE DATEIEN ÜBERTRAGUNG (MB) Completed 1/1 37/37 0.3/0.3 PHASE AKTIONEN Installationsphase 74/74 PHASE ELEMENTE Paketstatus-Updatephase 1/1 Abbildstatus-Updatephase 2/2
Den Service wieder aktivieren und prüfen:
root@iscsi-host:/# svcs iscsi/target STATE STIME FMRI online 13:23:56 svc:/network/iscsi/target:default
Alles läuft, es kann also mit der logical unit weiter gehen. Ich lege also das logische Gerät an mit dem Ziel des vorhin angelegten ZFS Volumes:
root@iscsi-host:/# sbdadm create-lu /dev/zvol/rdsk/iscsi-target-pool/iscsi_10gb-lun01 Created the following LU: GUID DATA SIZE SOURCE -------------------------------- ------------------- ---------------- 600144f051c247000000523ed0050001 10737418240 /dev/zvol/rdsk/iscsi-target-pool/iscsi_10gb-lun01
Vertrauen ist gut, Kontrolle ist besser! Also mal nachsehen ob alles angelegt ist und ob es auch „online“ ist 🙂 hier hilft wieder der stmfadm(in):
root@iscsi-host:/# stmfadm list-lu -v LU Name: 600144F051C247000000523ED0050001 Operational Status: Online Provider Name : sbd Alias : /dev/zvol/rdsk/iscsi-target-pool/iscsi_10gb-lun01 View Entry Count : 0 Data File : /dev/zvol/rdsk/iscsi-target-pool/iscsi_10gb-lun01 Meta File : not set Size : 10737418240 Block Size : 512 Management URL : not set Vendor ID : OI Product ID : COMSTAR Serial Num : not set Write Protect : Disabled Writeback Cache : Disabled Access State : Active
Damit der eigentliche Initiator es sehen kann, müssen wir dazu noch einen „view“ erstellen. Ich erstelle diesen mit Hilfe der eindeutigen GUID und prüfe ihn direkt im Anschluss:
root@iscsi-host:/# stmfadm add-view 600144F051C247000000523ED0050001 root@iscsi-host:/# stmfadm list-view -l 600144F051C247000000523ED0050001 View Entry: 0 Host group : All Target group : All LUN : 0
Zwischenstand:
– Ich habe alle nötigen Dienste.
– Ich habe 10GB ZFS Volume in einem extra Pool das ich nutzen möchte.
– Ich habe eine logical unit angelegt, welche dieses ZFS Volume wiederspiegelt.
– Ich habe dafür gesorgt das der initiator diese logical unit sehen kann.
Fehlt noch? Genau das Target:
root@iscsi-host:/# itadm create-target Target iqn.2010-09.org.openindiana:02:6c3939bf-f5e5-4f28-a8d0-d0f0bbb2e1c4 successfully created root@iscsi-host:/# itadm list-target -v TARGET NAME STATE SESSIONS iqn.2010-09.org.openindiana:02:6c3939bf-f5e5-4f28-a8d0-d0f0bbb2e1c4 online 0 alias: - auth: none (defaults) targetchapuser: - targetchapsecret: unset tpg-tags: default
Wie gehabt… Anlegen und zur Sicherheit noch einmal prüfen. Natürlich könnte ich den Namen des Targets ändern, soll aber schnell und einfach gehen, richtig?
Jetzt kann ich schon fast zur Microsoft Windows Maschine wechseln. Vorher sorge ich mit einem kurzen:
root@iscsi-host:/# devfsadm -i iscsi
…noch dafür dass mein konfiguriertes iSCSI Target ganz sicher im Discovery auftaucht!
Windows….
Ich lasse mich immer wieder von diesem Betriebssystem verarschen! Da will ich nur eben den Microsoft iSCSI-Initiator auf der Windows 7 Pro VM aktivieren um den Windows Part zu zeigen…. Da kommen bei der Installation so hässliche Fehlermeldungen wie:
"You do not have permission to update Windows. Please contact your system administrator." "Setup could not find the update.inf file needed to update your system." "Initiator-2.08-build3825-x64fre.exe"
Eine kurze Recherche zeigte mir meinen Fehler. Das Teil ist bei mir bereits installiert. Im Grunde habe ich für diese Erkentniss länger gebraucht als für die komplette Vorbereitung auf der Solaris Kiste 🙁 Nicht falsch verstehen, ich suche die Schuld nicht bei Windows! Ich habe halt einfach keine Ahnung von den Kisten.
Aber weiter im Text. Auf der Windows Seite habe ich folgendes gemacht:
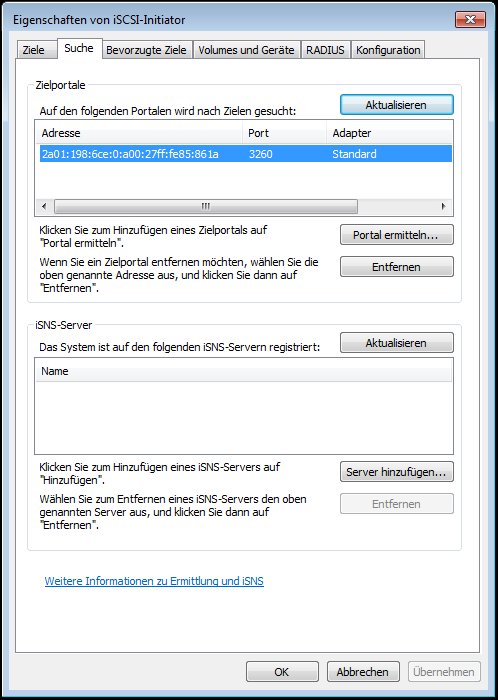
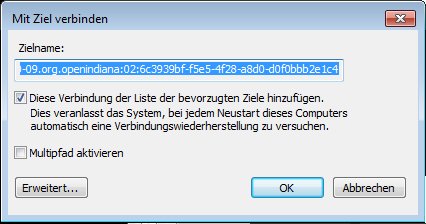
– Das Portal über die IPv6 Adresse ermitteln lassen.
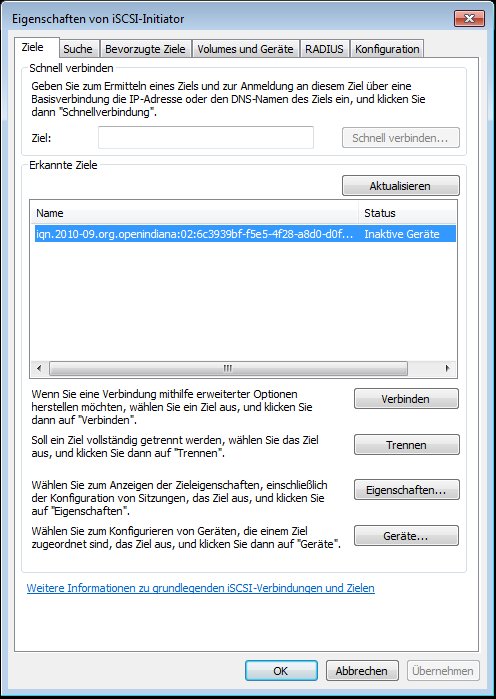
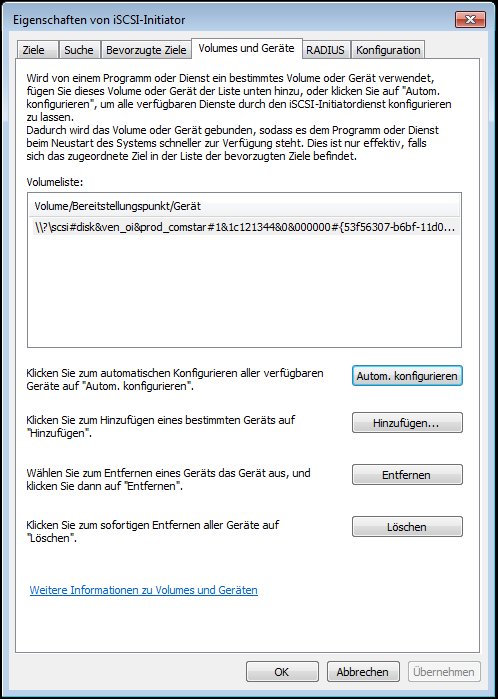
– Das Ziel gesucht und verbunden.
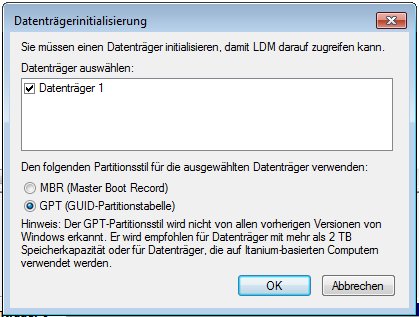
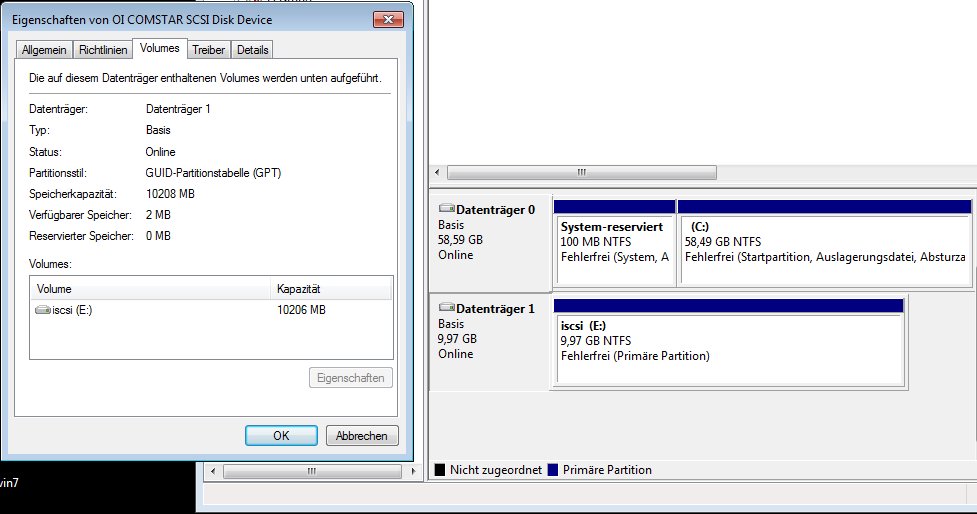
– Die neue „Festplatte“ in der Datenträgerverwaltung inizialisiert und auf diesem ein einfaches NTFS Volume erstellt.
Für den Microsoft Windows Teil habe ich ein paar Bilder erstellt 🙂
 |  |  |  |
 |  |  |  |